人材開発支援助成金とは?
従業員に専門知識や技術を習得させるための能力開発や研修費用の一部を、国が助成する制度です。助成金を利用することで、企業はより少ない負担で従業員のスキルアップを図ることができます。
※ 補助金の支給をお約束するものではございません。本情報は令和5年6月26日時点の厚生労働省発表資料に基づき作成しております。助成金申請時は、必ず最新の情報を厚生労働省のホームページ等でご確認ください。


Aidemy Businessは生成AIを始めとしたテクノロジーを駆使し、
業務と組織を変革できる自走型DX人材を育成するための
オンライン学習プラットフォームです。

※画面は開発中のものにつき、実際の仕様とは異なる場合があります。
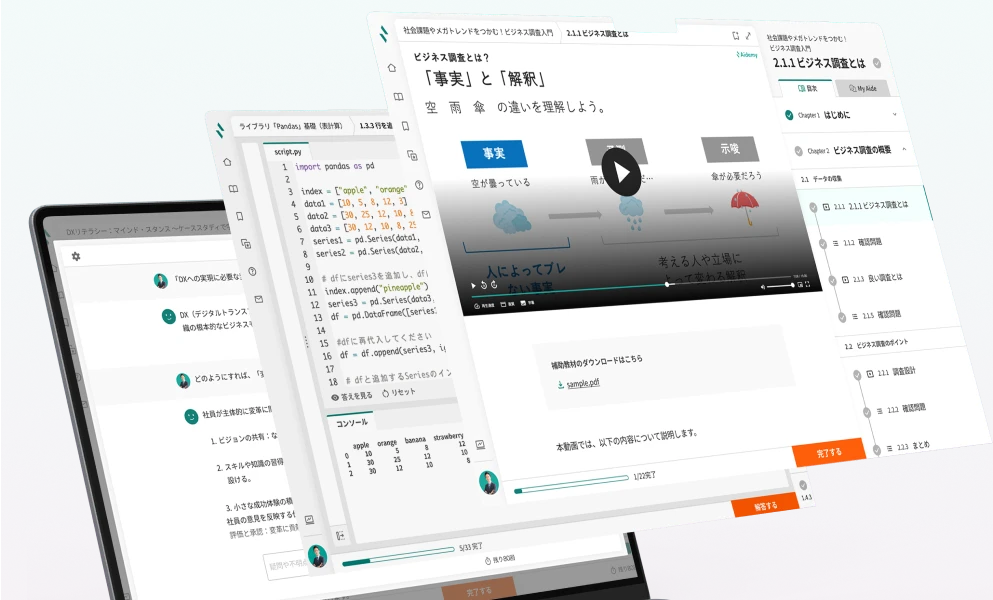
生成AIで業務効率化、Pythonプログラミングができる実務者から、Word・Excel・ITの基礎が分かる初学者までを、人材要件定義、スキルアセスメント、研修設計、学習促進を一気通貫で伴走可能なAidemy Businessが育成します。
豊富な支援実績から導き出したDX人材育成の成功パターンをベースに、人材要件定義・育成計画策定・効果測定まで一気通貫でご支援。
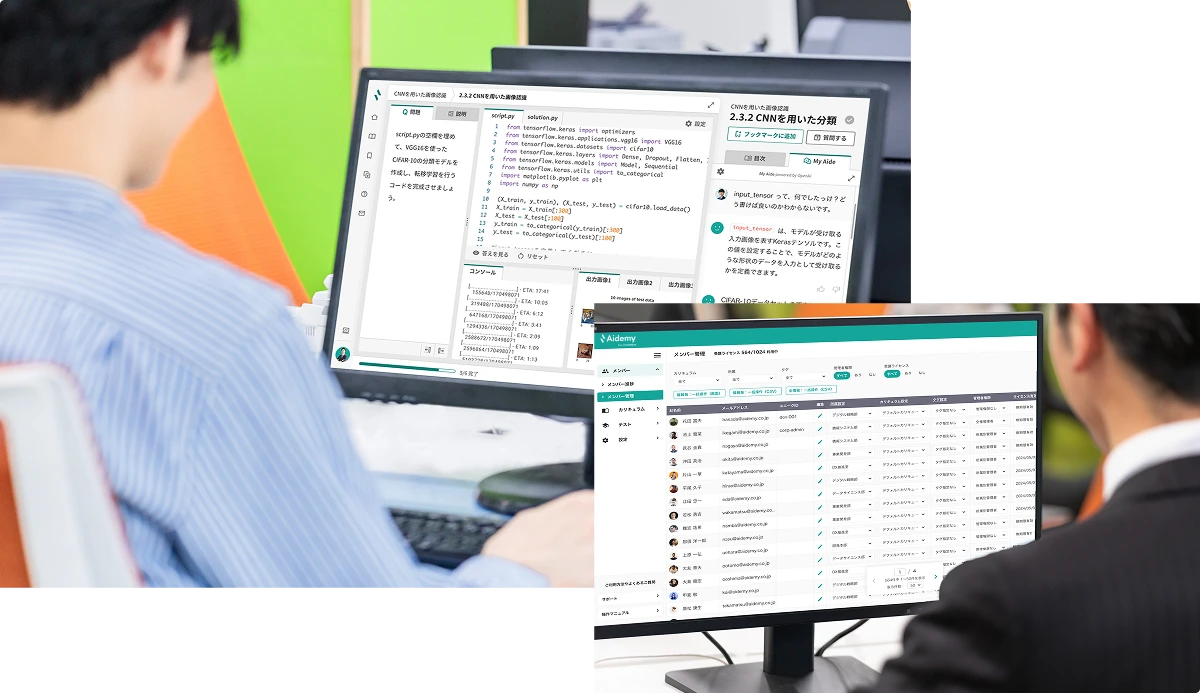
定義した人材要件別に専用の学習コンテンツとスキルデータが紐付いているため、従来は作成が難しかったデジタル人材育成の「研修設計」と「成果検証」が可能となっています。
右スクロール![]()

「デジタルスキル標準」に完全準拠したコースや生成AI関連のコースなどAI/DXの学習コースが250種以上。各コースは目的・職種・難易度別に細分化されているため、自社で運用している職務・職能別の要件定義の中に柔軟に組み込むことができます。
企業別の専用カリキュラムをご用意するため、多くの企業が陥る「誰に、何を、どの程度学習させるべきか分からない」といった問題も回避できます。

日本を代表するエンタープライズ企業を始め、様々な企業のDX人材育成を支援してきたプロフェッショナルが、最新のAI/DX動向、同業他社事例、過去の支援ノウハウをフル活用し、人材育成の先にあるAI/DXの「内製化」まで見据えて伴走支援。
企業別のビジネスモデル・DXビジョンを理解し、DX推進プロジェクトを成功に導きます。

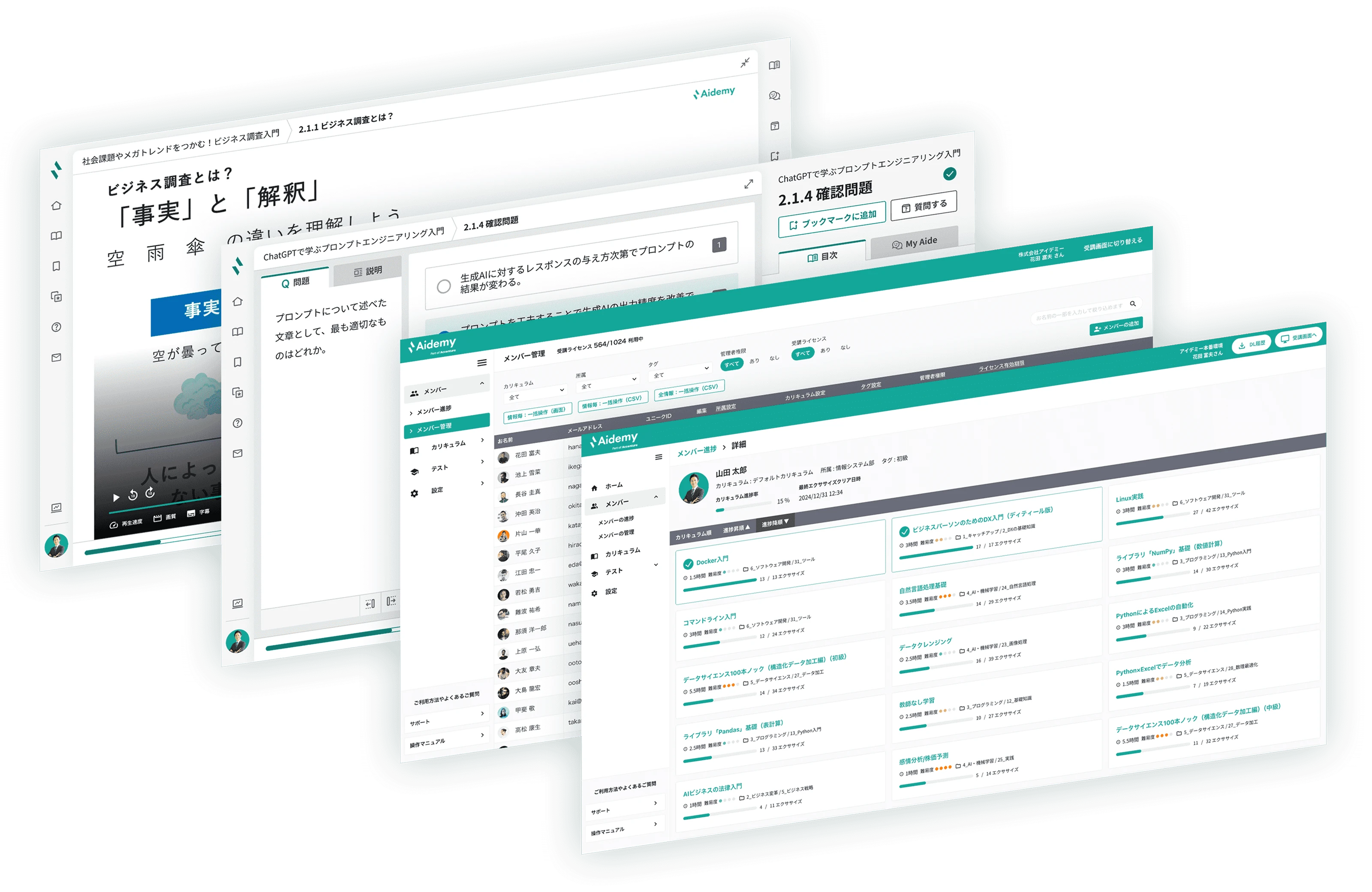
受講生の学習進捗管理、カリキュラム管理、理解度確認テスト、タグ管理、データのCSV出力など、管理者向け機能も充実しているため、結果の社内展開・分析も可能です。
また、LLM(大規模言語モデル)を使った対話型のパーソナルAIアシスタント「MyAide」が、受講者の専属アシスタントとして学習を強力かつリアルタイムでサポートいたします。
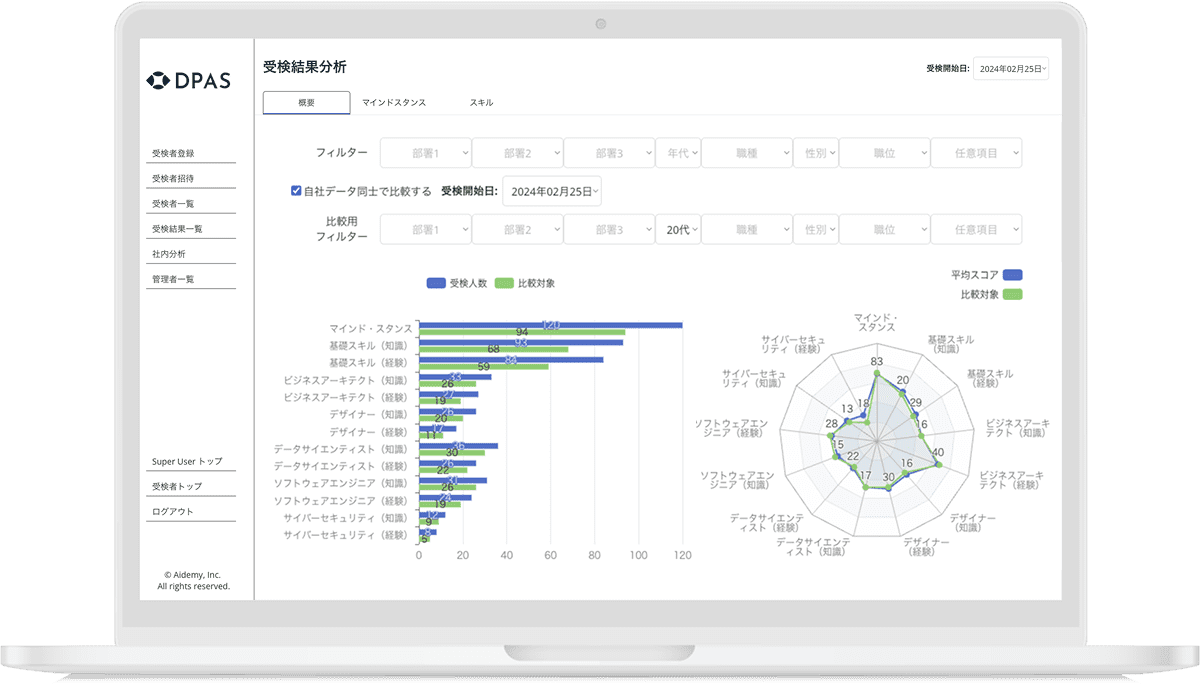
DXのスキルレベルを可視化するアセスメントテスト「DPAS(※別サービス)」と連動することで、Aidemy Business受講者がどれくらいスキルを習得したのか、客観的に把握することができます。
結果が可視化されることで、学習促進の取り組み、カリキュラムの見直し、投資対効果の把握など、データドリブンな人材育成サイクルを構築できます。

従業員に専門知識や技術を習得させるための能力開発や研修費用の一部を、国が助成する制度です。助成金を利用することで、企業はより少ない負担で従業員のスキルアップを図ることができます。
※ 補助金の支給をお約束するものではございません。本情報は令和5年6月26日時点の厚生労働省発表資料に基づき作成しております。助成金申請時は、必ず最新の情報を厚生労働省のホームページ等でご確認ください。
組織が変わる理由がわかる

ご面談企業様限定