
この記事は2021年4月21日に開催されたWebセミナー「事例に学ぶ 機械学習プロジェクトを成功に導くための基礎知識・勘所」のレポートです。
※記事化のために一部を抜粋・編集しています。
登壇者

嘉戸 裕希(かど ゆうき)
執行役員 事業本部 Modeloy事業部 部長 CDO
大学在学中よりフリーのウェブエンジニアとして多数の案件に携わる。複数企業にてCTOを歴任した後、株式会社ブログウォッチャー技術開発本部長としてビッグデータを活用したプロダクトの開発・運用を担当する。2018年に株式会社BEDORE(株式会社 PKSHA Technologyの自然言語処理部門子会社)では対話エンジンのプロダクトマネジャーを担当、株式会社PKSHA xOps出向後は機械学習プロジェクトの効率化を推進する。2021年1月より現職。
システム開発プロジェクトと機械学習プロジェクト
目次
- 1 一般的なシステム開発プロジェクトの全体像
- 2 機械学習プロジェクトの特徴
- 3 機械学習プロジェクトの全体像
- 4 機械学習プロジェクトで頻出する課題
- 5 機械学習プロジェクトの概要
- 6 プロジェクト企画フェーズ
- 7 プロジェクトPoCフェーズ
- 8 プロジェクト設計・開発フェーズ
- 9 プロジェクト運用フェーズ
- 10 自動応答の精度が低下し、再学習しても戻らない
- 11 コスト面の課題
- 12 ユーザー満足度の低下
- 13 Q. 共有知識はどの程度を想定すれば良いでしょうか。
- 14 Q. チャットボットの自動回答率90%以上というのは、実際のプロジェクトでも妥当な指標なのでしょうか。
- 15 Q. 機械学習のフレームワークとしてオープンソースソフトウェアを活用する場合、運用後に商用利用不可になる可能性を判断する手段はありますか。
一般的なシステム開発プロジェクトの全体像
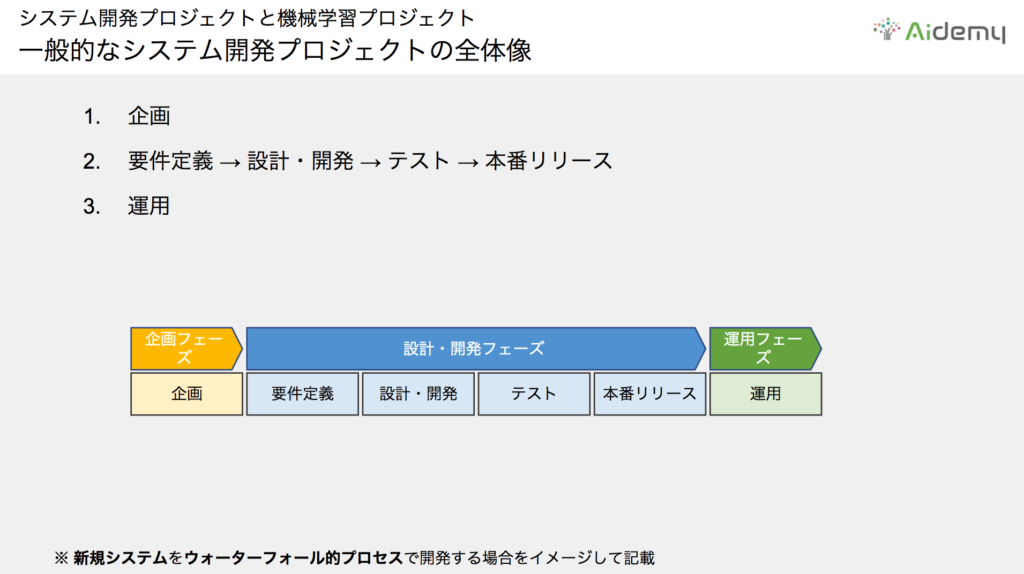
システム開発プロジェクトには、大きく分けて左から企画、設計・開発、運用の3つのフェーズがあります。一般的に、左から右へ流れるウォーターフォール型の古典的な開発手法が採用されています。
機械学習プロジェクトの特徴
機械学習プロジェクトが一般的なシステム開発と異なる点として、やってみないと分からないこと、精度に100%の保証ができないことの2点が挙げられます。
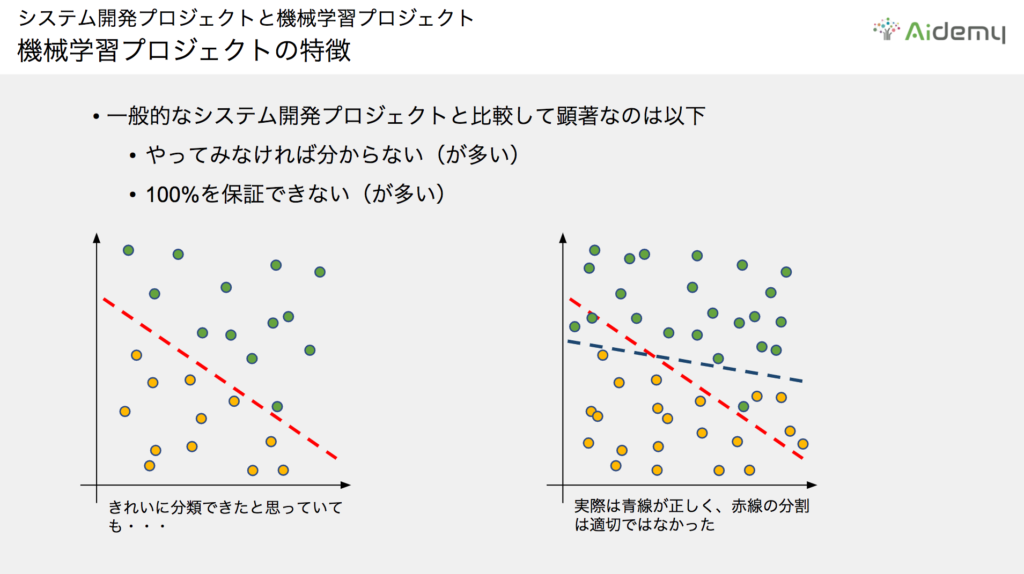
上のグラフには、二次元平面にオレンジと緑の点が示されています。これらを機械学習の手法を用いて上手く分離し、新しく点が与えられた時にどちらの色なのか判別したいとします。一見、左図のように赤の点線で上手く分割できそうだと感じても、右図のように点が増えると実際は青の点線が正しい分割になります(それでも緑の点が1つ下にはみ出ます)。これは例外値と言い、赤の点線で分割しようとすると正しく判別できない点が出てきてしまうという具体例です。
さらに難しいことに、実際は青の点線がどこか分からない、分離するための基準がわからないことの方がはるかに多いのです。つまり、現時点で判別できていても、今後出てくるデータを本当に正しく判別できるかどうかは分からない(=精度100%の保証ができない)ということになります。
そのため、データの判別を完全な自動化まで落とし込もうとするのは非常に大変、もしくは不可能に近いケースが多くみられます。このあたりが機械学習プロジェクトの大きな特徴です。
機械学習プロジェクトの全体像
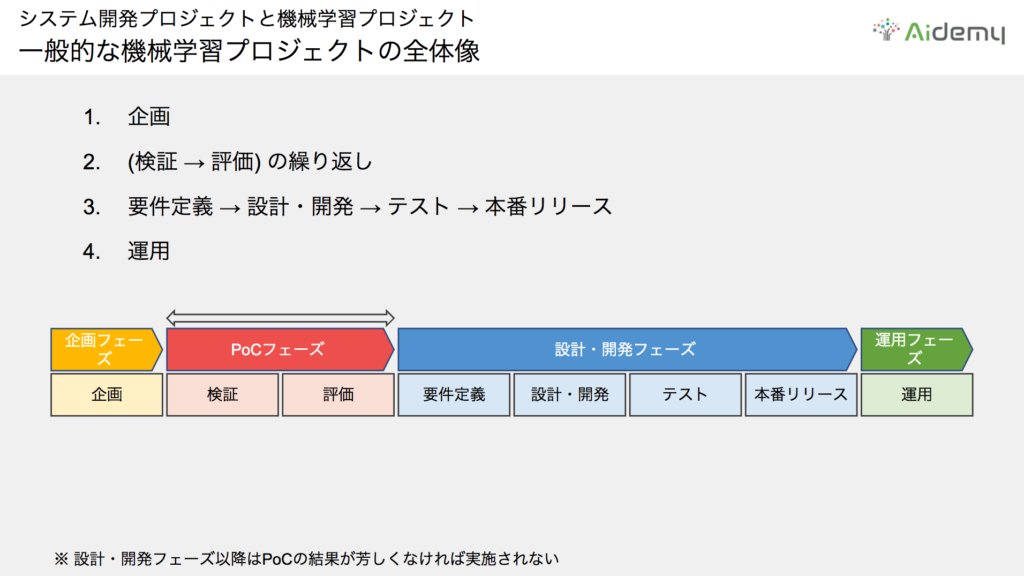
機械学習プロジェクトでは、企画フェーズの後に「PoC」というフェーズが入ります。これは「概念実証」を意味するProof of Conceptの略で、試作開発の前段階における検証やデモンストレーションを指します。開発前に検証フェーズを挟むことが、一般的な機械学習プロジェクトの進め方です。
最初のフェーズはプロジェクトの企画、次が実証実験を行うPoCフェーズです。機械学習の要素を使うことを検討した場合、それが本当に実用的で効果が出るのかを試します。PoCフェーズ上で白抜きの矢印が示しているように、ここでは検証を何度か繰り返します。私の経験上、1度で上手くいくことはあまりなく、3度くらいは繰り返し、評価指標を上げながら目標に近づけてモデル改善を行います。
このフェーズが追加されているのが、機械学習プロジェクトの大きな特徴かと思います。分からないことは試すしかない、ということです。
機械学習プロジェクトでは、実証実験のフェーズで目標の精度を出しても、ビジネスとして展開する際にコストが見合わない場合や手動の方がスピード感がある場合など、色々な事情で設計・開発フェーズまで行かないケースが圧倒的に多く、ここが最も難しい点です。システム開発の場合は本番まで進むことが多いですが、機械学習プロジェクトの場合はPoCフェーズを経て設計・開発フェーズに入れるかどうかが、最初の難所となります。

また、各フェーズにおいてプロジェクトを主導する職種も様々です。企画フェーズはビジネス職(企画、営業、マーケティング)、PoCフェーズでは、データサイエンティストがメインになるケースが多いです。その後実際に本番のシステムに入る場合にはソフトウェアエンジニアが主担当となるなど、フェーズごとに異なります。
それぞれのフェーズにおいて主担当のみが存在すればいいわけではなく、互いに協働する必要があります。設計・開発から運用を見据えた形で企画を行わなければ、作ってみたものの、実運用に組み込めないシステムになってしまうようなことが頻繁に起きます。この場合、ビジネス職であってもPoCフェーズの知識は非常に重要なのです。
同様に、各職種間で互いに専門領域以外の知識も必要となるわけですが、それぞれ専門性の高い領域であるため、分業して協働する形になります。「自分はデータサイエンティストなので、エンジニアリングは全く分からなくてもよい」というスタンスでは、チームとして上手くいかない課題もあるのです。
機械学習プロジェクトで頻出する課題
上図は、それぞれのフェーズで頻出する課題をまとめたものです。最初の企画フェーズでは、問題設定やKPIの妥当性といった課題がボトルネックとなります。
PoCフェーズではデータの利活用における課題が出てきます。例えば、データは保有しているがデータ量の不足、品質が良くないといったケースで、すぐに使える状態ではないことがしばしばあります。
さらにフェーズを進めると、セキュリティや非機能要件、災害時運用といった課題も発生します。例えば、何らかの原因で首都圏が壊滅的な打撃を受け、AWSのデータセンターが止まった場合のビジネスの継続判断についても、大企業は考える必要があります。
機械学習プロジェクトは上記を全て考えながら進めますが、あらゆる課題を回避してプロジェクトに大きな問題を起こさず進めることはとても困難です。
機械学習プロジェクトの事例(サンプル)
機械学習プロジェクトの概要
機械学習プロジェクトの事例を、弊社のサービス「Aidemy Business」をサンプルプロジェクトに置き換えてご紹介します。
なお、本サンプルプロジェクトはフィクションです。弊社のサービスを例示していますが、設定した課題も含め架空のものです。実在する名称や事実とは一切関係ありません。
Aidemy BusinessはAIを始めとする先端技術のオンライン学習サービスです。特徴は、AIなどのテクノロジーだけでなく、統計学や数学といった人工知能周辺領域の他、ビジネススキルやDXリテラシーを習得できる講座を有している点です。機械学習の利活用、プロジェクト推進の手法、事業企画などのビジネストピックまで幅広く網羅しています。また、それらの知識を専門のチューターに質問することで、さらに理解を深められるのも大きなポイントです。
昨今の情勢による巣ごもり需要の一環で学習サービスの需要が高まっており、ユーザー数が急増している状況を考慮の上お読みください。
まずは、本サンプルプロジェクトのために設定した課題を紹介します。
課題
- ユーザ数の急増に伴い質問数が増加し、質問に回答できるチューターが不足
- “よくある質問”でも回答に時間を要している
- 上記を原因として、適切なサービス提供に支障が出ると予測される
この課題は、「“よくある質問”にもすぐに回答できないなど、オペレーショナルな業務にさえ時間を要している」ケースを想定しています。社員が頑張って耐えてはいるが、このままではサービスの提供に支障が出るので何とか手を打たなければいけない、というのが本サンプルプロジェクトの状況です。
続いて、この状況を解決するための方法を可能な限り挙げていきます。
解決策の検討
- チューターを増員する
- 質問サービスの範囲を絞る(一部講座のみ対応など)
- 「質問対応プラン」と「質問非対応プラン」を用意する
- AI技術を活用する
解決策の案が出揃ったら、それぞれについて検討していきます。
チューターの増員がでれば話は早いのですが、問題は早急にチューターリソースを拡充することが難しい点です。チューターは誰にでもできる業務ではなく、コストの問題もあるため現実的ではないことが予想されます。サービスやプランに関する案については極力避けたいところですが、場合によってはサービス提供範囲の縮小や撤退も考えなければいけません。
そこで今回は「AI技術を活用する」という案から着想を得て、「チャットボットの導入」という解決策を採用します。
プロジェクト企画フェーズ
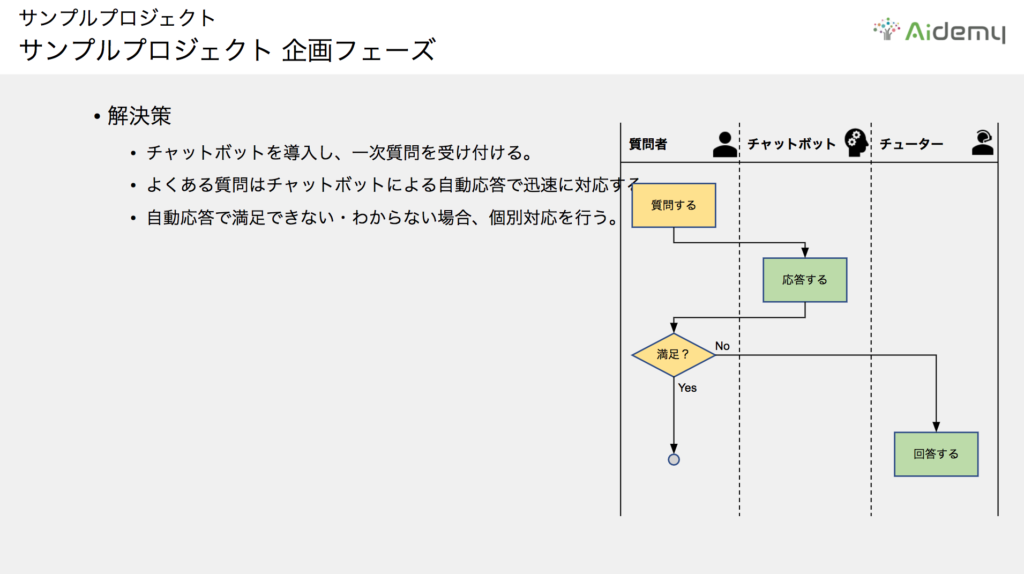
チャットボットによる自動応答で、“よくある質問”に対しては即座に回答します。そして「満足できない」「わからない」など、自動応答で回答できない複雑な質問に対しては、これまで通り個別の対応を行う、という解決策を企画として考えます。
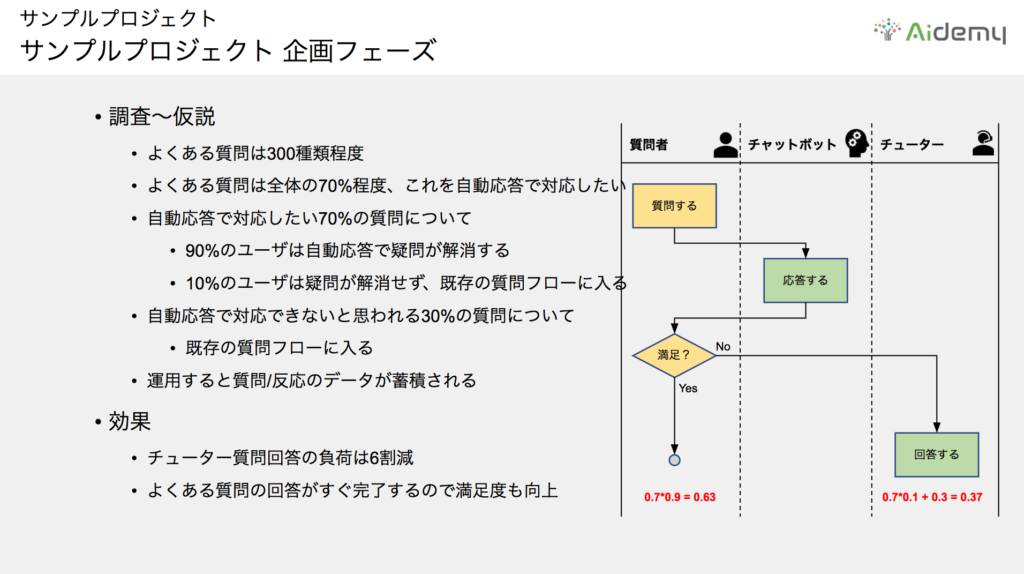
次に調査と仮説をまとめます。現時点までの質問履歴より、“よくある質問”は全体の70%を占めるため、自動応答化することでチューターの負荷を大幅に軽減できると考えました。ただし、自動応答で回答した“よくある質問”について、すべてのユーザーが満足してくれるかどうかはわかりません。
仮に90%のユーザーが“よくある質問”への自動応答で疑問を解消し、10%のユーザーが満足せずチューターに回答を求めると仮定すると、計算上はチューターの質問対応が63%減ることになります。
つまり、効果として考えられるのはチューター質問回答リソースの軽減と、“よくある質問”への即時性の高い回答という2点です。
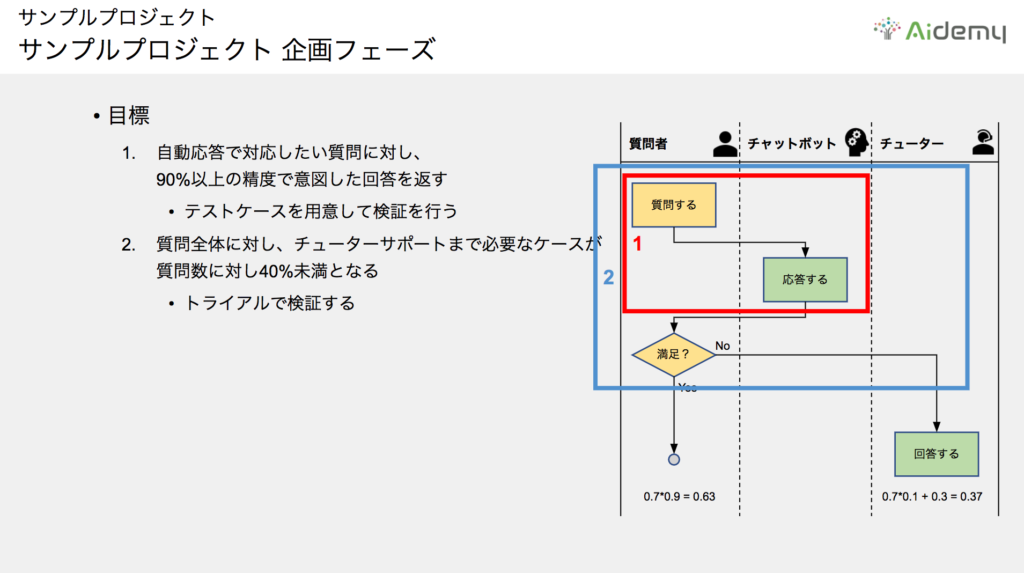
続いては、上述の仮説を検証するための目標設定です。プロジェクトの仮説検証には、測定できる目標値が非常に重要です。
目標は2点設定しました。まずは上図赤枠の「自動応答で対応したい質問に対し、チャットボットが90%以上の精度で意図した回答を返す」ことです。精度が50%程度では、満足度は高く見積もっても50%にしかなりません。ここでは90%以上の精度を狙いたいので、テストケースを用意して検証を行います。
2つ目は、青枠の「質問全体に対し、チューターサポートまで必要なケースが、質問数に対し40%未満となる」ことです。ここではチューター負荷を目標程度に下げるべく、トライアルを行って検証します。
プロジェクトPoCフェーズ
PoC(概念実証)フェーズでは仮説を検証するための実現方法を考えます。今回は比較的新しい手法である「ALBERT(軽量BERT)」を採用します。
自然言語処理といえば「BERT」が有名ですが、モデルサイズが大きいため、簡単なチャットボットへの導入では運用コストが大きすぎて、ビジネスが成り立たないデメリットがあります。その点、「ALBERT(軽量BERT)」では、より軽い仕組みでの運用が実現できます。
仕様については、質問履歴の調査からわかった300種類程度の“よくある質問”に対する自動応答を、1つのモデルで実現します。検証結果はここでは重要ではないので、前述の目標を全て達成できたとして先に進みます。
プロジェクト設計・開発フェーズ
続いては設計・開発フェーズです。
今回の実装では「画面の右下にあるチャットウィンドウから質問すると、自動応答が返ってくる」という、チャットボットによくあるUIを採用して実装します。仕様の説明をしなくてもユーザーが直感的に使うことができるため、このような王道のデザインを踏襲することは有効です。
また、ユーザーの視点では自動応答の即時性も重要であるため、インスタンスは常時起動にします。さらに運用後の改善を考慮し、ユーザーの質問、チャットボットの回答、ユーザーの満足度を全てログに残すようなシステム構築を行います。
さらに、必要に応じてモデルを再学習し、その都度新しいものに入れ替える運用を考えました。
プロジェクト運用フェーズ
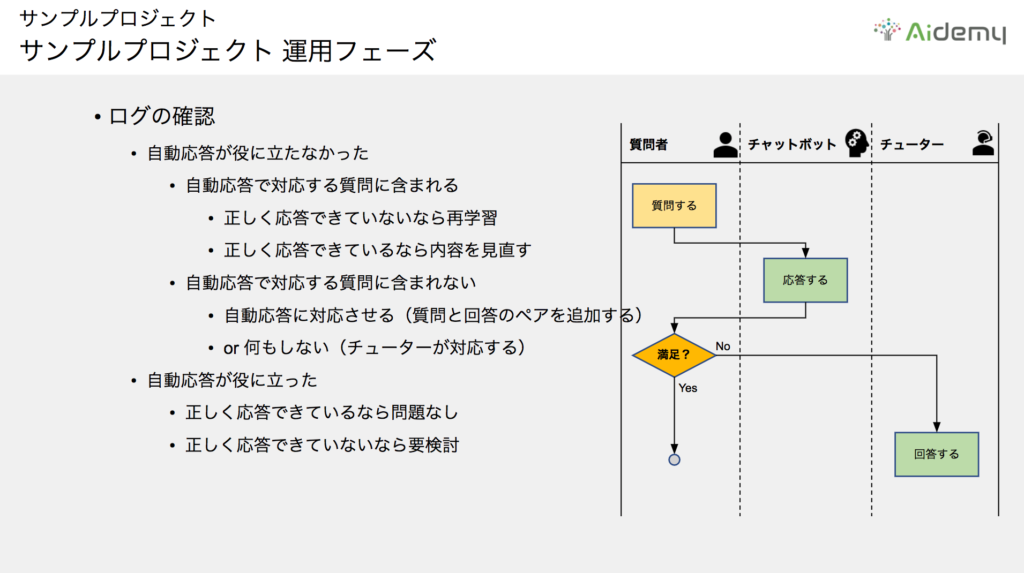
最後に運用フェーズです。ログを確認し、モデルの精度を向上させることでより良いサービスの提供に繋げます。
ここでは、チャットボットでの自動応答運用で目標が達成できなかった場合の改善・運用に絞って考えます。
自動応答で対応した質問
まず、チャットボットが正しく応答できていない場合が考えられます。例えば「Pythonとは何ですか?」という質問に対する想定回答は「プログラミング言語です」となるはずですが、これを「ヘビです」と答えてしまうケースです。この場合は、データセットを追加してモデルの再学習を行い、正しく回答できるように修正します。
次に、ユーザーがチャットボットの自動応答では満足できない場合です。「Pythonとは何ですか?」という質問に対して、「script言語です」や「AI領域で注目を集めています」という回答では質問者のニーズを満たせないようなケースでは、回答内容を見直し、詳細な修正を加えるタスクが考えられます。
よくある質問に含まれなかった質問
この場合も2通りの対応が考えられます。
チャットボットの自動応答に対応させるために、新たな質問と回答のペアを追加して再学習させるパターンと、これまで通りチューターが対応する、つまり何もしないパターンです。
機械学習プロジェクトにおける課題別の対処方法
ここでは、上記のプロジェクトを進める中で発生した3つの課題と解決策を紹介します。
自動応答の精度が低下し、再学習しても戻らない
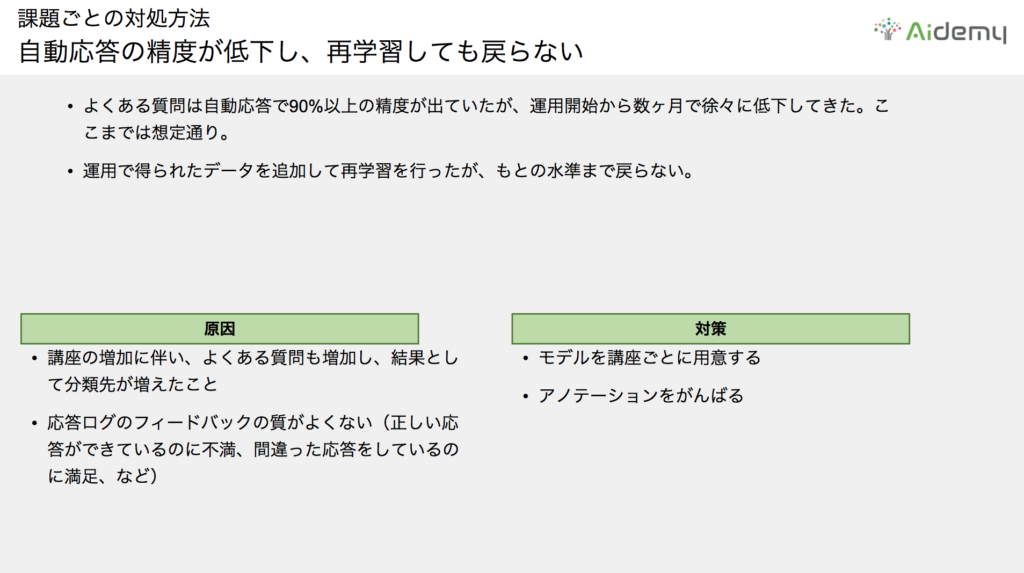
まず、「自動応答の精度が運用開始から数カ月で少しずつ低下し、再学習しても元の水準まで戻らない」という課題です。
Aidemy Businessの事業を進める上で、新規コンテンツの追加は欠かせません。学習コンテンツを追加すると、“よくある質問”も比例して増加します。その結果、元々300だった“よくある質問”の種類が増えて分類問題の難易度が向上し、今までと同じ方法では自動応答の精度を維持できなくなりました。
また、ここでは回答ログのフィードバックを元にした精度の改善を考えていました。しかし、実際に正しい応答はできているがユーザーニーズを満たせない(ユーザーニーズの基準が高すぎる)場合や、チャットボットが間違った回答をしているのに満足のボタンを押してしまうといったヒューマンエラーのケースもあり、回答ログのフィードバックを上手く活用できず、なかなか再学習が上手くいかないことも課題の要因となりました。
この課題の対策としては、モデルを分割することが最もシンプルです。講座の増加に伴い1つのモデルでの対応が難しくなった場合、回答ログのフィードバックの質が良くなければ、まずはログを全て見ることに近い対応をせざるを得なくなります。
今回は全てのログを正確に見てアノテーション(データに注釈を付けて教師データを作り出す作業)を進めるのが良いと思います。
コスト面の課題

次に、コスト面での課題です。
今回のサンプルプロジェクトはAIを活用することが適切となる設定にしていますが、実際のプロジェクトの場合はより簡単な方法、例えばExcelを使って解決するケースや、同様の機能を提供するSaaSを使う方法も考えられます。
AIのモデルを作成せずともシンプルに早く対応できるため、できるだけ最小リソースで可能な手法から順に検討していくことが有効です。機械学習を用いるか否かは、投資対効果の面でも非常に重要なのです。
ユーザー満足度の低下

最後は、ユーザー満足度の低下という課題です。
前述した2つの課題を回避して運用を継続したものの、結果としてユーザー満足度が低下し、解約率が増加傾向にある場合、そもそもチャットボットによる自動応答がユーザーに求められている機能ではなかったことが考えられます。
例えば、実際にこのようなサービスを利用するのは、機械ではなく人が回答してくれることに価値を感じるユーザーが多い、という可能性が考えられます。
解決策としては、事前に一部の講座で、ユーザー満足度を指標に含めた検証を行うことが挙げられます。運用前に小さく試しておけ、検証の段階で対応方法が不適切だと気付ける可能性があります。ユーザーに対するアンケートや、講座のABテストなども有効な手段として考えられます。
今回のサンプルプロジェクトでは、検証の目標値をチューターの工数削減と自動応答の満足度に置きましたが、効果測定のためのKPI設定の妥当性については正しく検証されなかったことになります。
機械学習プロジェクトを成功に導く勘所
機械学習プロジェクトは、PoC(実証実験)フェーズの存在によって不確実性が非常に高くなります。PoCで結果が出ず、本番実装まで進まないケースが多くあります。従来のシステム開発に比べると世の中に出回っている事例も少なく、機会学習そのものの歴史も浅いため、難度が非常に高いのです。
それでも、私たちは機械学習を活用して世の中の問題を解いていく必要があります。公開されている事例を知っておくことで回避できる課題も多く存在するので、情報収集が重要になります。過去の事例がなく、やってみないとわからない課題については、小さく試して検証を重ねることで対処するのが良いでしょう。耐久性に優れたアジリティーの高い組織やチーム体制を作ることも、企業のAI導入やDX推進において非常に重要なポイントになります。
組織という観点では、専門性を持った人材が効果的に協働することが大切です。ビジネススキル、データサイエンススキル、エンジニアリングスキル、それぞれについてエキスパートである人材を集め、全領域に詳しいチーム構成を目指すことが現実的かつ理想的です。
効果的な協働には、チームの共有知識(リテラシー)が非常に重要です。一人ひとりが自分の専門領域以外に関してもある程度の基礎知識を持っていることで、プロジェクトにおけるコミュニケーションが円滑に進みます。アイデミーのAidemy Businessは、このような共有知識を身に付ける際に非常に有用なツールであるため、ご自身の専門領域ではない部分にも一歩踏み出す目的でご活用頂ければ嬉しく思います。
質疑応答
Q. 共有知識はどの程度を想定すれば良いでしょうか。
嘉戸
幅広い知識なので基礎的な部分のみで十分だと思います。
例えば、AI領域にはわかりやすい指標として「G検定」という資格があります。基礎的な知識を網羅できるため、G検定の取得如何でリテラシーは大きく異なります。
エンジニアリング領域に関してはIPA(情報処理推進機構)が実施している「基本情報技術者試験」がおすすめです。改訂も頻繁に行われており、内容は確かなものです。ただし、簡単に取れる合格できる試験ではありません。
ビジネス領域の基礎知識については、営業・マーケティング手法に関する書籍を読み、ここ5年程度の最新の営業・マーケティングプロセスに触れてみることから始めるのが良いと思います。
Q. チャットボットの自動回答率90%以上というのは、実際のプロジェクトでも妥当な指標なのでしょうか。
嘉戸
はい。今回のように質問数が300~500程度である場合、“よくある質問”に回答するタイプのチャットボットでは、90%以上の質問に回答できることが多いと思います。
Q. 機械学習のフレームワークとしてオープンソースソフトウェアを活用する場合、運用後に商用利用不可になる可能性を判断する手段はありますか。
嘉戸
商用利用不可などの方針変更について判断することは、現時点では不可能だと考えています。最近の機械学習フレームワークでは、TensorFlowや国産のChainerが開発中止になったというニュースもありましたので、そういった不確実性もリスクとして織り込んだ上で、ビジネスを展開するしかないと思います。
